Data Mining: A Beginner’s Guide to Key Concepts and Tasks
In an era where information is abundant and data is the new currency, extracting valuable insights from the vast digital landscape has become paramount. Imagine being able to uncover hidden patterns, predict trends, and make informed decisions that drive success. Welcome, let’s explore the Core Concept of Data Mining. Here I will be sharing my understanding and knowledge with you. Whether you’re a curious learner, an aspiring analyst, or a seasoned professional, this blog is your gateway to understanding the core concepts that underpin the fascinating world of data mining.
Table of Contents:
- History and Purpose of Data Mining
- Why mine data
- Introduction to Data Mining
- Applications
- Data Attributes, Attributes Type, Data Objects, and Data Type in Data Mining
- Introduction to Data Attributes
- Types of Data Attributes
- Types of Data
- Data preprocessing
- Basic Data Exploration Techniques
- Similarity Measures
- Correlation Measures
- Visualization Techniques
1:History and Purpose of Data Mining
Why Mine data?
Data mining, the process of extracting valuable insights from large datasets, has become a vital practice in today’s data-driven world. The motivation behind data mining lies in the desire to uncover hidden patterns, extract meaningful insights, and gain valuable knowledge that can drive informed decision-making. By delving into data, organizations can reveal correlations, trends, and outliers that might not be apparent through traditional analysis methods. Data mining enables businesses to optimize their operations, enhance customer experiences, and ultimately, achieve competitive advantages in their respective industries.
Introduction to Data Mining
There are several definitions of data mining. Below are two of them.
“Non-trivial extraction of implicit, previously unknown and potentially useful information from data”
“Exploration & analysis, by automatic or semi-automatic means, of large quantities of data to discover meaningful patterns”
So in simple words, this is what I understood. Data mining, kind of a branch of data analysis. Given large amounts of data, using programming, statistical techniques, AI, ML, or any other automated tools to figure out a useful pattern and knowledge as per requirement from the data.
It is important to understand what is Not Data Mining is. For example, Querying a word dictionary for the meaning of a word is not Data Mining. Rather, finding out which words can be grouped according to their context is data mining.
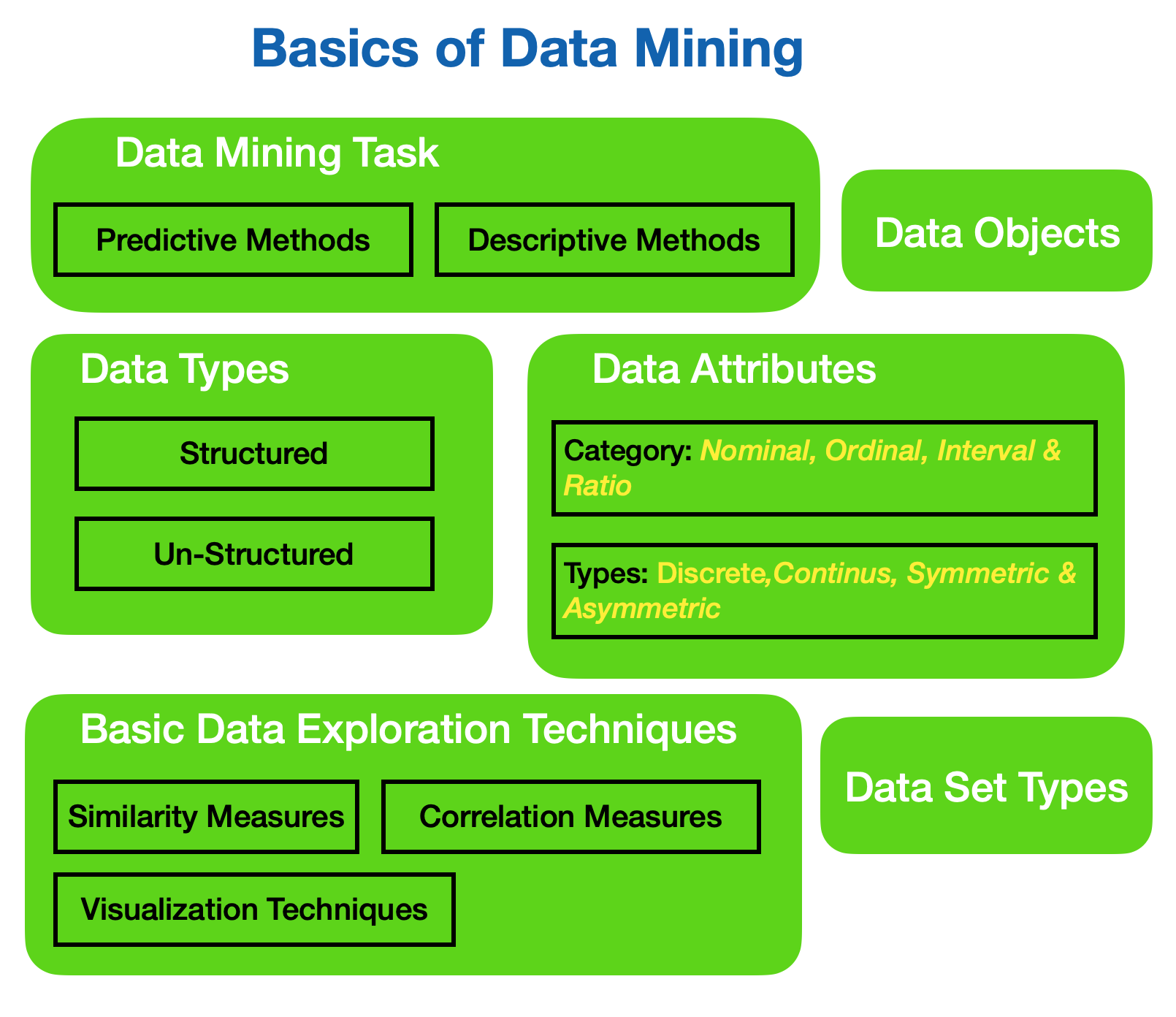
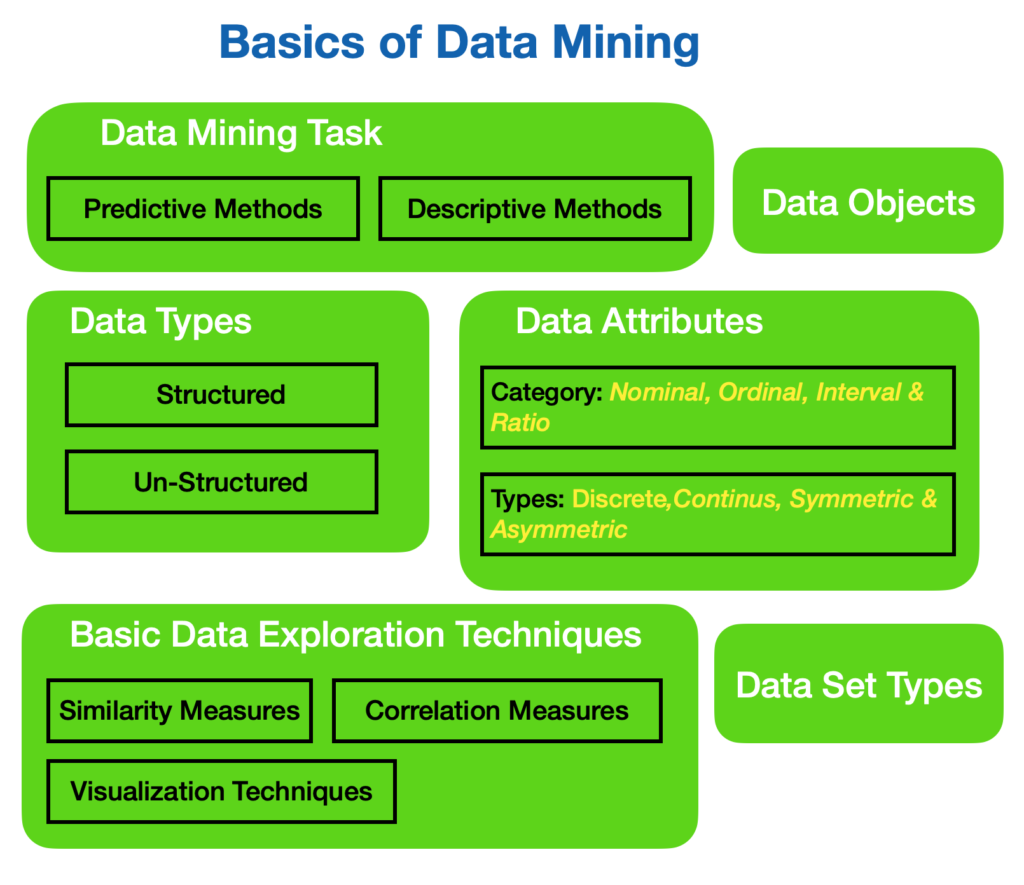
Data Mining Task
- Predictive Methods: means use some variable to predict unknown or future values of other variables
The predictive method includes techniques like classifications, Regression, deviation detection
- Descriptive Methods: means finding human understandable patterns that give insight into the data
The descriptive method includes techniques like; clustering and Association Rule discovery
Historical Overview
The origins of data mining can be traced back to the 1980s when the field started gaining recognition and significance. Initially, data mining primarily focused on statistical models and exploratory data analysis techniques. However, with the advent of more powerful computers and the proliferation of data, data mining evolved to encompass advanced machine learning algorithms. Over time, data mining techniques have become indispensable in various industries such as finance, healthcare, retail, and marketing.
Applications
Data mining has made significant contributions to various fields, laying the foundation for its current importance. In finance, it has been used to detect fraud and predict market trends. In healthcare, it has aided in disease diagnosis and treatment effectiveness analysis. For retailers, data mining has facilitated customer segmentation and personalized marketing campaigns. The applications of data mining are vast and diverse, making it an essential practice in today’s data-centric world.
2: Data Attributes Needed for Data Mining
Introduction to Data Attributes
Data attributes refer to the characteristics, qualities, and properties of the data being analyzed. They play a crucial role in the data mining process as they provide the basis for extracting meaningful insights. Attributes can include numerical values, categorical labels, or textual descriptions that define each data instance. Understanding and analyzing these attributes enables data mining algorithms to uncover patterns, correlations, and trends within the dataset.
NOTE: So, In the data table, you can consider the columns as attributes and each row as objects.
Types of Data Attributes
Data attributes can be categorized into different types, including nominal, ordinal, interval, and ratio. Nominal attributes represent qualitative data with no intrinsic order, such as colors or categories. Ordinal attributes also represent qualitative data but have an inherent order, such as rankings or satisfaction levels. Interval attributes deal with numerical data and have a consistent interval between values, while ratio attributes also involve numerical data but with a meaningful zero point. For instance, age would be an interval attribute, whereas income would be a ratio attribute.
Feel free to connect with me to understand what each type of attribute is and its properties.
Types of Data
Data can be broadly classified as structured and unstructured. Structured data refers to organized datasets with a predefined schema, making them easily searchable and analyzable using traditional database management systems. Examples of structured data include spreadsheets and relational databases.
In contrast, unstructured data lacks a predefined structure, making it more challenging to analyze. Examples of unstructured data include text documents, social media posts, and multimedia content. Unstructured data presents both challenges and opportunities in data mining, as it requires advanced text mining and natural language processing techniques to extract meaningful insights.
Data Preprocessing
Before data mining can take place, data preprocessing is necessary to ensure data quality and consistency. This step involves several tasks, such as data cleaning to remove irrelevant or inconsistent entries, handling missing values to avoid biased analysis, and outlier detection to identify unusual data points that may skew the results. Other processes that one could undertake are aggregation, sampling, dimensionality reduction, feature subset selection, attribute transformation, and so on. Data preprocessing plays a vital role in enhancing the accuracy and reliability of data mining results.
3: Initial Data Exploration Techniques
Similarity Measures
Similarity measures are essential in data mining as they quantify the similarity or dissimilarity between data instances. Various similarity metrics, such as Euclidean distance, Cosine similarity, and Jaccard similarity, are used to compare and evaluate how closely related two data instances are. These measures allow data mining algorithms to identify the dataset’s clusters, patterns, and anomalies, enabling more accurate analysis and prediction.
Correlation Measures
Correlation measures gauge the relationship and dependency between different attributes within a dataset. By quantifying the statistical association between variables, correlation measures help identify patterns and dependencies that might not be apparent through simple analysis. Commonly used correlation measures include the Pearson correlation coefficient and Spearman’s rank correlation coefficient. Understanding attribute correlations is crucial in gaining insights into the relationships within the data and informing decision-making processes.
Visualization Techniques
Visualization techniques play a crucial role in initial data exploration. Scatter plots, heat maps, and histograms are powerful tools that provide visual representations of data patterns, distributions, and relationships. Scatter plots display the relationship between two variables, heatmaps illustrate data density and correlations, and histograms present data distributions. Visualization techniques enable data miners to gain a comprehensive understanding of the dataset, identify outliers, and generate hypotheses for further analysis.
In conclusion, data mining is a powerful practice that uncovers hidden insights in vast amounts of data. By exploring its history, understanding the importance of data attributes, and reviewing initial data exploration techniques, one can appreciate the value and potential of data mining in various fields. As technology advances, data mining will undoubtedly play an increasingly critical role in driving informed decision-making and generating valuable knowledge from our data-rich world.
Hope I have made it easy to understand Classification and its types. If you like this article and think it was easy to understand and might help someone you know, do share it with them. Thank You! See you soon.
If you have any questions or comments feel free to reach me at.
Checkout out my guides covering other Data Mining concepts.