Everything You Need to Know About Classification and its Types: A Comprehensive Blog for Beginners and Experts
In an age where data reigns supreme and insights hold the key to innovation, the art of classification stands as an invaluable beacon in the realm of data science.. classification is one of the most essential tools for extracting valuable insights from data. It is a fundamental human activity that helps us to understand and organize the world around us. Classification is used in all areas of knowledge, including science, technology, engineering, mathematics, and the humanities. In this blog, we will provide a comprehensive guide to classification, covering everything from the core concepts to the most popular classification algorithms. Whether you are a curious novice or beginner or an experienced data scientist, this blog will give you the knowledge and skills you need for a richer understanding of classification.
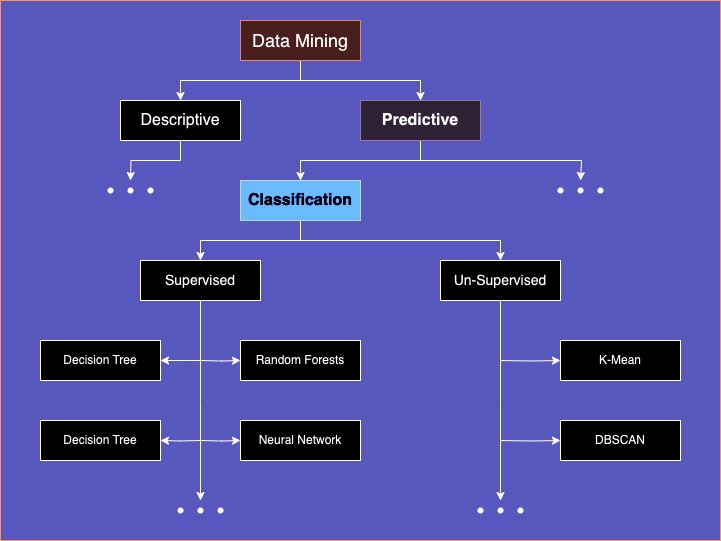
Table of Contents:
- Understanding Classification Basics
- Types of Classification Methods
- Supervised Classification
- Definition and Principle
- Popular Algorithms in Supervised Classification
- Decision Trees
- Naïve Bayes
- Support Vector Machines
- Unsupervised Classification
- Definition and Principle
- Clustering Algorithms in Unsupervised Classification
- K-means Clustering
- Hierarchical Clustering
- DBSCAN
- Semi-supervised Classification
- Definition and Application
- Techniques Used in Semi-supervised Classification
- Supervised Classification
- Summary
- FAQs
I. Understanding Classification Basics
A. Definition of Classification
Classification is a fundamental concept in data science and machine learning that involves organizing data into different categories, groups, or classes based on specific properties, features, or attributes. By assigning data points to predefined classes, classification algorithms aim to predict the class or category of new, unseen data. The primary goal of classification is to simplify complex information by grouping similar items together, which makes it easier to understand, analyze, or make decisions based on the categorized data.
B. Importance of Classification in Various Fields
Classification plays a crucial role in a wide range of fields, including finance, healthcare, marketing, and more.
- Science: Classification is used to organize and understand the natural world. For example, scientists use classification to group plants and animals into species, genera, families, orders, classes, phyla, and kingdoms. This helps scientists to understand the relationships between different organisms and to make predictions about their behavior.
- Medicine: Classification is used to diagnose diseases and to develop treatments. For example, doctors use classification to identify different types of cancer and to recommend the best course of treatment for each patient.
- Business: Classification is used to segment customers, identify market trends, and develop new products and services. For example, businesses use classification to group customers into different segments based on their demographics, purchase history, and other factors. This information can then be used to develop targeted marketing campaigns and to create products and services that meet the needs of specific customer segments.
- Information technology: Classification is used to organize and manage data, filter spam, and recommend products and services to users. For example, email providers use classification to filter spam messages and to send relevant content to their users.
- Finance: Classification is used to assess risk, to make investment decisions, and to detect fraud. For example, banks use classification to assess the creditworthiness of loan applicants and to identify fraudulent transactions.
By accurately categorizing data, classification techniques enable various industries to make informed decisions and gain valuable insights.
C. Evolution of Classification Techniques
Over the years, classification techniques have evolved significantly. From traditional statistical models to the emergence of complex machine learning algorithms, the field of classification has experienced remarkable advancements. These advancements have been driven by advancements in computing power, the availability of vast amounts of data, and the development of sophisticated algorithms.
- Early classification techniques: Early classification techniques were based on simple rules and heuristics. For example, one early classification technique for spam filtering was to look for keywords such as “free” and “money” in the email subject line.
- Statistical classification techniques: Statistical classification techniques use statistical methods to learn from data and to develop classification models. For example, a statistical classification model for spam filtering might be trained on a dataset of labeled emails, with the goal of learning to distinguish between spam and legitimate emails.
- Machine learning classification techniques: Machine learning classification techniques use machine learning algorithms to learn from data and to develop classification models. Machine learning algorithms are able to learn complex patterns in data, which makes them well-suited for classification tasks. For example, a machine learning classification model for spam filtering might be trained on a dataset of labeled emails, with the goal of learning to distinguish between spam and legitimate emails with high accuracy.
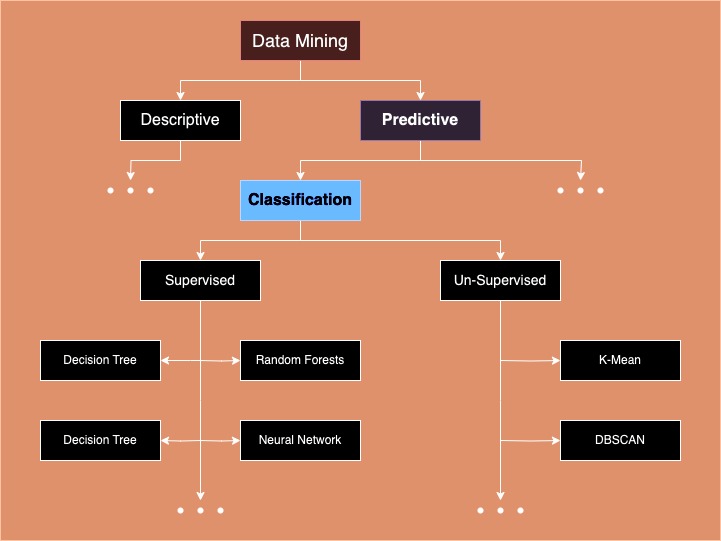
II. Types of Classification Methods
A. Supervised Classification
Supervised classification is a technique that involves training a model on labeled data, where each data point is assigned a known class. The model learns from this labeled data and can then make predictions on new, unseen data. The principle behind supervised classification is to find patterns in the training data that can help classify future observations accurately.
1. Definition and Principle
Supervised classification relies on a target variable or label in the training data that determines the class membership. This target variable is typically pre-assigned by humans or generated through an existing knowledge base. The algorithm uses this labeled data to learn the relationships between input features and their corresponding labels. By comparing the input features with the known labels, the model learns to recognize patterns and make predictions or classify new, unseen data.
2. Popular Algorithms in Supervised Classification
Supervised classification encompasses various algorithms. Supervised classification offers a wide range of algorithms to choose from, each with its. The choice of algorithm often depends on the nature of the problem, the dataset, and the desired outcomes. Not to forget the algorithm’s own strengths and weaknesses. Here are five commonly used ones:
a. Decision Trees
Decision trees are hierarchical structures that guide the classification process by splitting the data based on different features. They use a set of if-else conditions to create a tree-like or flowchart-like structure, making them easy to interpret. The structures that recursively split the data based on features to make classification decisions. They are interpretable and can handle both numerical and categorical data.
b. Naïve Bayes
Naïve Bayes is a probabilistic algorithm based on Bayes’ theorem. It assumes that all features are conditionally independent of each other given the class label, simplifying the computations. Despite this assumption, Naïve Bayes can produce accurate results and is particularly useful for text classification tasks and spam detection.
c. Support Vector Machines
Support Vector Machines (SVM) is a powerful algorithm that creates a hyperplane or decision boundary to separate different classes. The goal is to maximize the margin between the hyperplane and the closest points of each class, thus achieving optimal classification. SVMs are powerful algorithms for binary and multiclass classification.
d. Random Forest
Random forests are a type of supervised classification algorithm that combines multiple decision trees to produce a more accurate classification model. Random forests are less sensitive to overfitting than decision trees, and they can be used to classify data with a variety of different data types.
e. Neural Networks
Neural networks are a type of supervised classification algorithm that learns to classify data points by using a layered network of interconnected nodes. Neural networks can be trained to classify complex data patterns, but they are often more difficult to interpret than other supervised classification algorithms.
Deep neural networks, including feedforward networks, convolutional neural networks (CNNs), and recurrent neural networks (RNNs), are powerful for complex classification tasks, such as image and text classification.
B. Unsupervised Classification
Unsupervised classification, unlike supervised classification, does not rely on labeled data. Instead, it aims to find inherent patterns or structures within the data without any predefined classes or labels. Unsupervised classification, also known as clustering, is a type of machine learning and data analysis technique.
1. Definition and Principle
In unsupervised classification, the algorithm analyzes the input features and organizes the data into natural clusters or groups based on their similarities, differences, or patterns within a dataset. The main objective is to discover underlying patterns or relationships that can help gain insights into the data.
2. Clustering Algorithms in Unsupervised Classification
Unsupervised classification involves various clustering algorithms. Each with its own approach to grouping data points based on their similarity or distance from each other. Here are some popular clustering algorithms used in unsupervised classification:
a. K-means Clustering
K-means clustering is a popular algorithm that partitions data into K clusters, where K is a predefined number. It iteratively assigns data points to the nearest centroid, recalculates the centroid, and repeats until convergence. In other words, the k-means clustering algorithm works by iteratively assigning data points to the cluster with the closest mean.
b. Hierarchical Clustering
Hierarchical clustering builds a hierarchy of clusters by either merging or splitting them based on their similarities. It creates a dendrogram (a tree-like structure) that illustrates the relationships between clusters, allowing for a deeper understanding of the data. Hierarchical clustering algorithms can be used to produce both divisive (top-down) and agglomerative (bottom-up) clusterings.
b. DBSCAN
DBSCAN stands for Density-Based Spatial Clustering of Applications with Noise. DBSCAN is a density-based clustering algorithm that groups data points based on their density. It identifies dense regions as clusters and isolates low-density data points as noise. DBSCAN is able to identify clusters of arbitrary shape, and it is not sensitive to outliers.
C. Semi-supervised Classification
Semi-supervised classification combines elements of both supervised and unsupervised classification. It leverages a small portion of labeled data along with a larger amount of unlabeled data to train the model.
1. Definition and Application
Semi-supervised classification is particularly useful when acquiring labeled data is expensive or time-consuming. It can provide improved accuracy by utilizing the available labeled data and the additional information provided by the unlabeled data.
2. Techniques used in Semi-supervised Classification
Various techniques are used in semi-supervised classification, including:
a. Self-training:
The Self-training model initially trains on labeled data and then uses its own predictions to label the unlabeled data. These predictions are treated as pseudo-labels, and the unlabeled data is incrementally incorporated into the training set.
The pseudo-labeled data is a set of unlabeled data points that have been assigned labels by the model.
b. Co-training
Co-training is a semi-supervised approach where multiple views or representations of the data are considered. Models are trained separately on each view and share information with each other to make predictions on unlabeled data.
In other words, it’s an algorithm that works by training two supervised classification models on two different views of the data. The two views of the data should be complementary, such that the two models can learn different information from the data.
c. Transductive learning:
Transductive learning is a machine learning paradigm that falls under the broader category of semi-supervised learning. It’s a specific type of semi-supervised learning that focuses on making predictions for unlabeled data points within the same dataset used for training. Unlike traditional inductive learning, which aims to build a model that generalizes to new, unseen data, transductive learning concentrates on making predictions only for the specific unlabeled instances present in the dataset.
III. Summary
Classification remains an essential pillar of data science and machine learning. By effectively categorizing data into meaningful classes, organizations can extract valuable insights, facilitate decision-making, and unlock numerous opportunities for innovation and growth. As data continues to grow in volume and complexity, mastering classification techniques becomes increasingly crucial for deriving actionable knowledge from the vast amounts of data available.
If you have any questions, need further guidance, or seek consulting services, feel free to get in touch with me. You can reach out to me through this Contact Form to discuss your specific needs and requirements.
IV. FAQs
A. What is the difference between supervised and unsupervised classification?
Supervised classification relies on labeled data to train a model and predict future instances, while unsupervised classification discovers patterns and structures within the data without any predefined labels. Supervised classification requires prior knowledge about the classes, whereas unsupervised classification aims to find inherent relationships and groupings without prior knowledge.
B. Which classification algorithm is best for my dataset?
The best classification algorithm depends on various factors, including the nature of the data, the size of the dataset, and the specific classification task. Different algorithms excel in distinct scenarios. It is recommended to experiment with multiple algorithms, evaluate their performance using appropriate metrics, and choose the algorithm that yields the best results for your dataset.
C. Why is classification important in data science?
Classification is essential in data science because it enables organizations to make sense of data, extract insights, automate decision-making, and solve a wide range of real-world problems. It plays a crucial role in fields like healthcare, finance, marketing, and more.
D. What are some real-world applications of classification?
Classification is used in a wide range of applications, including spam email detection, disease diagnosis, image recognition, sentiment analysis, credit scoring, and recommendation systems, to name a few.
E. What are some challenges in classification?
Challenges in classification include dealing with imbalanced datasets, feature selection, overfitting, model interpretability, and handling noisy data. Selecting appropriate evaluation metrics is also crucial for assessing model performance.
Hope I have made it easy to understand Classification and its types. If you like this article and think it was easy to understand and might help someone you know, do share it with them. Thank You! See you soon.
If you have any questions or comments feel free to reach me at.
Checkout out my guides covering other Data Mining concepts.